Optimising vocab learning (with some help from Python)
The number of words and phrases in a given language is overwhelming; it is impressive that a non-native speaker can become fluent in a foreign language at all.
Conventional wisdom tells us that a learner only reaches such a level of mastery through years of immersion – living, speaking and breathing the language every day – that allow them to internalise not only the sheer multitude of words, but also the mass of idioms, collocations and subtle meanings that, together, give them an intuitive knowledge of that language.
Taking a look at this enormous learning task – the absorption of thousands of words and phrases in a foreign language – I thought that there must be a way for students to learn more quickly, more comprehensively, and with more enjoyment in the daily learning exercise. Since any small improvements in the efficiency of the learning process would scale up thousands of times, I knew that investing time to optimise it would pay dividends in days and weeks of saved studying time.
So I wrote a program intended to serve as this tool that could automate the learning process.
Find my project on GitHub here.
This post outlines the theory and thinking behind the project itself. Please get in touch if you have any thoughts or suggestions!
1. Learn in descending order of frequency:
The first and simplest strategy to optimise study time is to focus on high-frequency words. Commonly, language learners are taught to learn the words and phrases that they personally encounter when they are exposed to content in their target language. The issue with this approach is two-fold:
- First, manually copying down words takes up studying time which could be better spent learning new material.
- Secondly, learning words without respect to their frequency doesn’t take advantage of the huge law of diminishing returns when it comes to the frequency of words; learning a few high-frequency words can be just as useful as learning hundreds of low-frequency ones, simply because the former are much more likely to appear in speech and writing.
This bar chart shows the exponential decay in the frequency of each group of 100 words, starting at 500-600th most frequent words in Russian (words taken from Russian National Corpus frequency list, and their frequencies taken from a parallel corpus search):
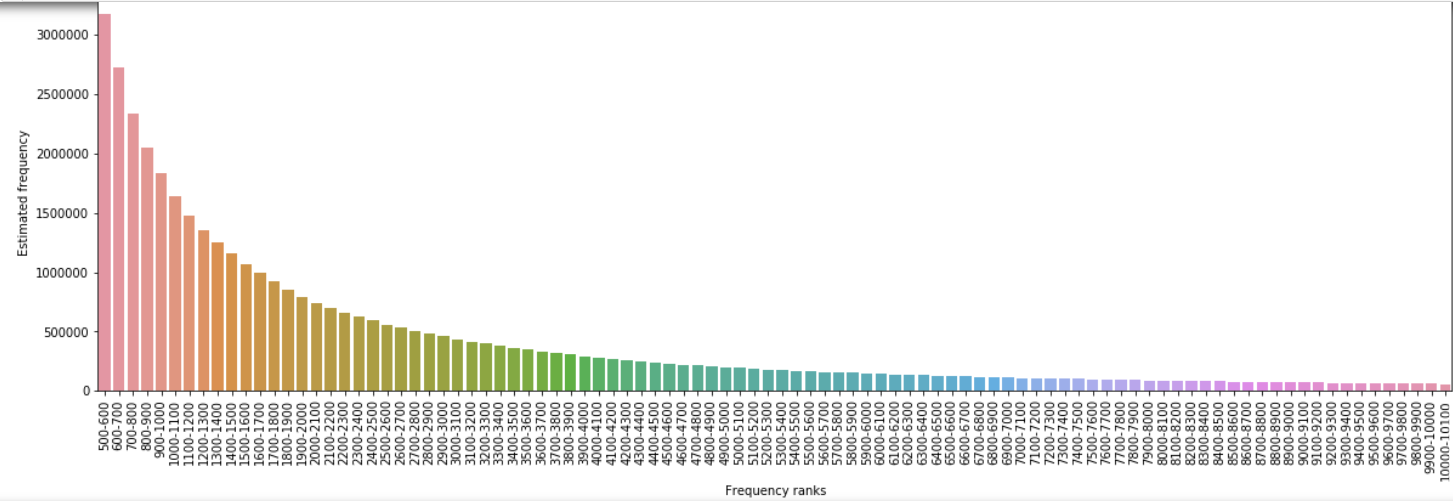
So how do we solve this?
a) With a frequency list
The simple solution to this is to learn in descending frequency order according to a frequency list of the whole language. These lists are calculated based on a huge corpus (body of texts) in the language. In my case, I used the one from the Russian National Corpus. Similar lists can be found online for many world languages.
b) With a corpus
A frequency list alone doesn’t give us enough data to make more detailed insights about word and phrase frequency. So instead, for my project I also used a huge parallel corpus (a dataset of translated sentence pairs) that can be queried to find more granular data on individual word meanings and collocations.
2. Learn multiple meanings:
The second principle of the system is to learn not individual words, but rather individual word meanings. This aims to account for the inherent semantic ambiguity of natural languages; the same word can have multiple different meanings, and the correct meaning can only be determined from context. Take, for example, the multiple meanings of the English word squash:
- As a verb:
- She squashed the sandwich
- I squashed into the middle of the crowd
- The defeat squashed her high spirits
- As a noun:
- Orange squash
- The squash club
From this, we see the necessity to learn multiple meanings, so that, for example, when a learner of English comes across squash in a sentence, they understand the intended sense of the word in its context. To make this learning more precise and effective, my program calculates the frequency of each meaning of a given word and labels the flashcard testing each meaning by its frequency. In this way, that flashcard can be ranked in the deck exactly according to its frequency. This accounts for the fact that some meanings of a word are significantly more common — and therefore more useful to learn — than others.
3. Learn collocations as well as individual words:
The third tactic to boost the efficacy of vocab learning is to identify and learn idioms and collocations.
Collocation = The habitual juxtaposition of a particular word with another word or words with a frequency greater than chance.
All languages are more than just thousands of individual words, but rather, a huge set of common patterns. These patterns — or collocations — exist everywhere in natural language, because they are easy both to produce and to understand. Learning collocations is an essential step in learning a language to fluency. Think: “to do progress” versus “to make progress”, “in total daylight” versus “in broad daylight”, “to stimulate someone’s interest” versus “to pique someone’s interest”. These are the kinds of patterns that a learner must know - without which, despite even the most honed grammar and pronunciation, they will find it impossible to speak like a native.